NLDs (“Natural Language Disambiguators”) can be used in place of LLMs or SLMs when you only need to disambiguate among a set of structured commands. They run in milliseconds, fast enough for real-time filtering and autocomplete on the front-end, and are robust to differences in phrasing, reordering of tokens, and extraneous tokens that don’t affect semantics. (“I want to return my order”, “order return”, and “my order has a problem, I’d like to return it” can all be parsed by the same NLD spec).
Here’s a demo for a hypothetical online bookstore:
The parsing is all being done on the front-end, and the user gets real-time suggestions as they type. It’s rarely necessary to even finish typing a full phrase.
In comparison, here’s what LLM-based intent classification looks and feels like:
LLM-based intent classification is much slower and gives no feedback until hitting submit. And then it’s “thinking”… for a while. A slugglish and unreliable UX isn’t suddenly fine just because we call it “AI”.
The NLDs experience is faster and more discoverable, since rich autocomplete suggestions are provided in real-time without a round trip to the server and without having to talk to a third-party LLM service.
How do they work?
NLDs build on the insight that disambiguating among a finite set of possibilities is a much easier problem than parsing arbitrary natural language. If you’re familiar with parser combinator libraries common in functional programming, NLDs are a bit like that, but with a few twists:
- Instead of the input being a sequence, it’s a position annotated multiset, roughly a map from token to the set of positions where that token appears. This structure means that filler words not mentioned by the NLD are automatically ignored (in “please change my address”, the tokens “please” and “my” are ignored), and the parser is robust to permutations of phrasing (“can I change my address?” and “address change” can be parsed by the same spec even though the tokens appear in different orders).1
- An NLD uses weighted nondetermism to explore multiple parses at once, preferring parses that have shorter edit distances to the canonical form given by the spec. This also lets them cope nicely with synonyms and misspellings without generating a combinatorial explosion at runtime.
On this second point, consider the following NLD:
tuple2 (words ["change", "update"]) (word "address")This will correctly parse “I’d like to update my address” or “address change”, returning the canonical form ("change", "address") for both. The first form has more filler words between the two tokens, has them in a different order, and uses a synonym for “change”, so this would be weighted less and may lose out to another parse which is a better fit if there’s significant ambiguity in the set of commands.
NLD specs can be produced via a coding assistant, effectively distilling the LLM’s knowledge and “internal thesaurus” down to a fully deterministic, tiny, and extremely fast natural language “parser” that is tailored to the domain.
You can see an implementation of NLDs here and the README has numerous examples. That implementation is in Unison, but the ideas port just fine to many other programming languages.
Limitations and comparison to LLMs
Aside from their blistering fast performance and support for real-time completions, NLDs have the nice property that they know what they don’t know. It’s a simple model of self-knowledge: a query missing any of the elements that appear in valid commands won’t be parsed. The UI can surface this as an empty state with a curated collection of possibilities:
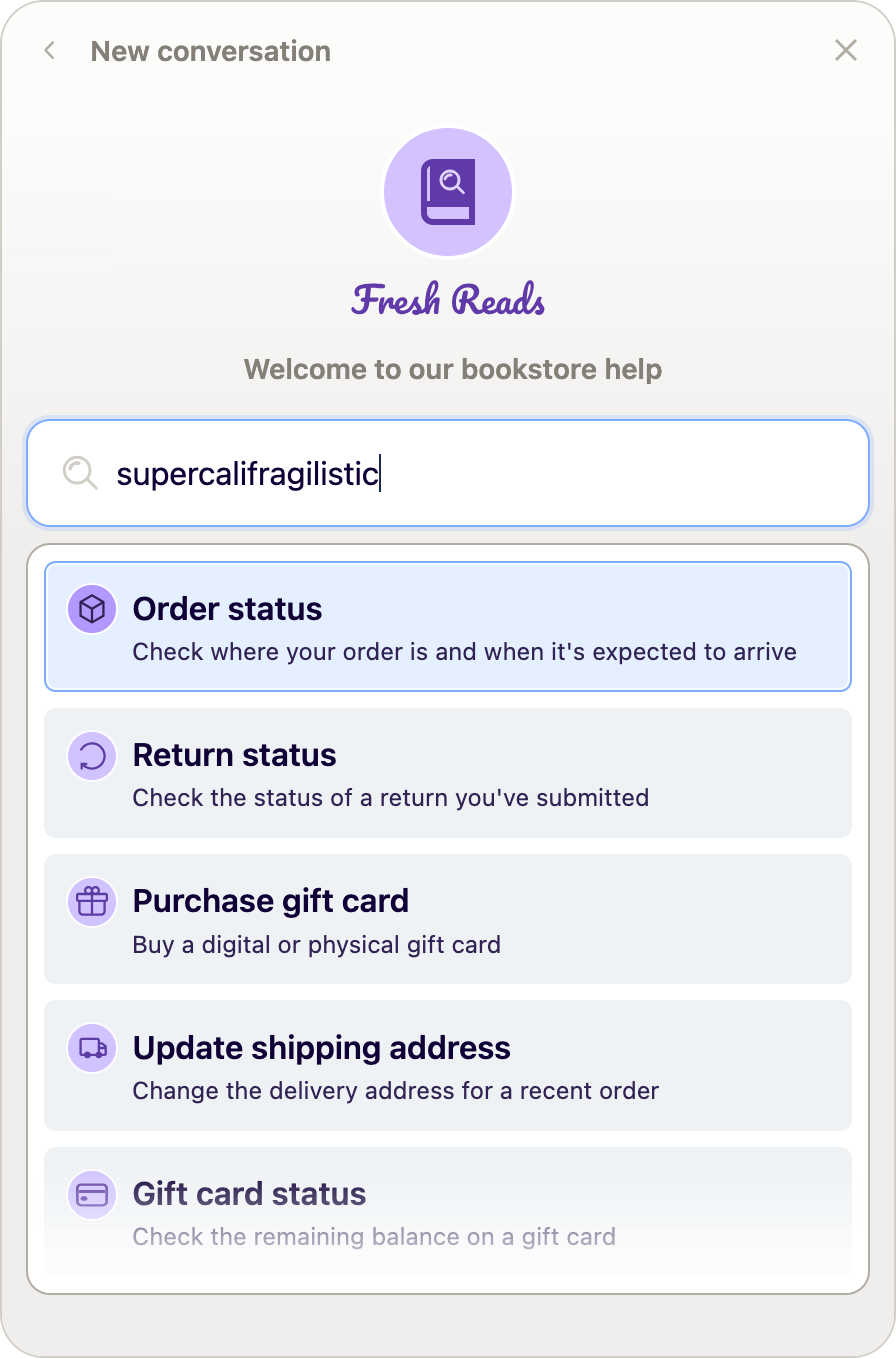
The input doesn’t correspond to any known possibility, so the UI shows a default menu of options.
In comparison, when LLMs are being used for intent classification (say, with structured generation), there’s always the chance that unexpected input will be mapped to a random command. One often compensates for this by having an “unknown” command and designing a prompt that hopefully steers the LLM toward selecting it if the model thinks it doesn’t know the answer. But this prompt must be tuned for reliability, and this work must be done anew everywhere LLMs are being used for intent classification.
NLDs are by design not as powerful as LLMs. An LLM can interpret queries like “change my shipping address to the one that’s in the state whose capital is Boston” or “solve this logic puzzle and purchase a gift card whose amount equals the puzzle solution”. But these capabilities aren’t typically useful since people don’t phrase their queries in such a circuitous way.
A more interesting limitation is that LLMs will understand that “cat” and “feline” are closely related, whereas an NLD must explicitly specify synonyms (and it can attach weights to these synonyms to convey how “far away” they are). This information can be produced manually by a domain expert, or LLMs are quite good at producing NLD specs.2
What makes NLDs work well despite this limitation is that in a finite domain, there just aren’t that many token synonyms users will plausibly type in real queries. The NLD structure is already by design robust to differences in phrasing (“I’d like to cancel my order”, “my order has a problem, cancel it”, “please cancel my order”, are all fine). And for an invididual sub-phrase or token like “cancel”, a relatively small list of synonyms that can be used interchangeably is often sufficient for good results (“cancel”, “cancellation”, “halt”, “stop”). The discoverability of real-time autocomplete means users are quickly taught the phrasings that work, and they needn’t even finish an entire query. For instance, just typing “order” will show completions for actions like “cancel order” or “order status”.
A UI with good real-time autocomplete can be an overall better experience than a high latency UI that’s a bit more flexible in what shape of input it accepts. At the end of the day, users need to know how to convey their intent. We can think of LLMs usage as perhaps making it more likely that users will guess a way of conveying intent without prior training on the UI. But the UI of a text box and a submit button isn’t great. It’s really too open-ended, encouraging users to think of the system as a general intelligence capable of responding to all inputs, when in fact the system is often only capable of a very narrow class of computations.
An NLD-based input control with rich real-time autocomplete teaches users what is valid and how to convey intent for the domain. The user is never frustrated after entering a lengthy input only to find the system has no idea what to do with it. Nor is the user ever shown hallucinations or something nonsensical based on incorrect assumptions. They are in the loop and can stop typing as soon as one of the autocomplete suggestions is what they want, without having to finish a full query. Overall: they can often accomplish their goals more efficiently than an equivalent system that used LLMs for the same thing.
Some “agentic” applications don’t need LLMs at all
It feels like LLMs have become a default tool for a huge variety of problems, even when simpler, cheaper, and faster approaches are available. NLDs are just one example.
In this post, we demonstrate use of NLDs within a computational conversation to create reliable and useful support bots that don’t use LLMs at all. The results are striking. We’ve come to accept high latency and unreliability from bots, with long pauses between conversational turns and hallucinations the norm. It’s embarrassing, and we can do a lot better.
If you’re working in this area or like the vision here or want a custom bot for your app or website, we’d love to hear from you. Shoot us an email at acid-burn example dotcom .
Footnotes
-
In this respect, they are reminiscent of a keyword spotting + slot filling system common in pre-ML systems, but with some differences: keyword spotting and slot filling are interleaved in an NLD, and NLDs use token position to guide weighted nondeterminism, allowing commands to have overlap of some tokens without generating ambiguity. Unlike KWS systems, NLD grammars are also compositional and handle synonyms nicely. ↩
-
It’s also possible to build an NLD library in which tokens are vectors produced by an embedding model and token matching uses vector similarity. This has some advantages, but a tradeoff is that it may no longer be possible to run it entirely on the front-end, making the autocomplete experience less snappy. ↩